生成AIによるコード生成が開発現場に急速に浸透する中、表面的な生産性向上の裏で深刻な問題が顕在化しています。コード品質の低下、レビューコストの増大、そして開発者自身がコードの詳細を把握できなくなるという事態が広がっています。
この記事では、Mark Seemannによって書かれた書籍「脳に収まるコードの書き方」にて提唱されているフラクタルアーキテクチャの概念がこの解決策となりうるかを考察しました。
AIコーディングにおけるパラドックス
AIコーディングの世界で開発者が新しい課題と認識し始めているのが、「本当に開発は早く・効率的になったのか?」という問題です。AIが生成したコードをそのままリリースできたことはどれくらいあるか。結局人間が介入しており、想像していたような劇的変化には辿り着けていないのではないか。こんな疑問を抱き、話し始める開発者が私のまわりでも目につくようになりました。
実際、2025年に Model Evaluation and Threat Research(METR)が実施した研究では、私たちの感覚と異なる結果が報告されています。経験豊富なオープンソース開発者16名を対象とした無作為化比較試験において、AIツールを使用した場合の完了時間は、使用しない場合と比較して19パーセント増加していました。
最も注目すべきは、認知の歪みです。開発者たちは研究開始前にAIが完了時間を24パーセント短縮すると予測し、研究終了後も20パーセント改善したと認識していました。しかし客観的なデータは、19パーセントの減速を示していました。アナリストは、この現象について「組織は開発者の満足度と生産性を混同するリスクがある」とレポートでコメントしています。ツールのユーザー体験と実際の生産性を混同せずに評価することは、個々の開発者が意識的に行うにはなかなか難しい課題のように感じます。正しく開発効率を評価するには、個人個人の体感に基づく定性データだけでなく、チームやプロジェクト単位での変化もモニタリングする必要がありそうです。
AIコーディングによるコード品質の低下
実装時間が伸びている可能性以外にも、問題が報告されています。GitClearが実施した研究では、2020年から2024年にかけて、Google、Microsoft、Meta、大企業を含む2億1100万行のコード変更を分析した結果、コード品質の明確な劣化傾向が観測されたと報告しています。
リファクタリングに関連する変更行の割合は、2021年の25パーセントから2024年には10パーセント未満へと急落しました。対照的に、コピー・アンド・ペーストと分類される行は、8.3パーセントから12.3パーセントへと上昇しています。2024年に5行以上の重複コードブロックの頻度が8倍に増加し、2年前と比較して10倍の高い重複率を示したという調査結果もでており、AIコーディングツールが重複したコードを生成しやすい現状に近い結果が出ているともいえそうです。
GitClearは調査結果を「AI生成コードは、訪問したリポジトリのDRY原則を侵害しがちな一時的な貢献者に似ている。」とまとめています。課題の解決は迅速に行えるが、長期的な保守性とモジュール性を犠牲にする可能性が高いと考えることができそうです。
レビュー負荷の増加
品質の低下と開発速度の減速は、人間によるレビュー負荷の増加にもつながっています。AIコーディングによる長期的な保守性の低下を防止するため、人間がコードをレビューするワークフローが選ばれがちです。
Qodoが実施した2025年の調査では、600人以上の開発者のうち、76パーセントを超える開発者が頻繁なハルシネーション(AIによる誤った出力)に遭遇し、人間によるチェックなしにAI生成コードを出荷することを避けていることが明らかになりました。つまり、AIがコードを高速生成する一方で、レビューステップがボトルネックと化しているのです。
コードをレビュワーが理解して評価する速度よりも、コードが生成される速度が早くなった結果、レビュワーの認知負荷が急激に増加しているともいえます。
フラクタルアーキテクチャによる認知負荷軽減の可能性
Mark Seemannは著書『脳に収まるコードの書き方』において、フラクタルアーキテクチャという概念を提唱しています。これは、コードのあらゆる抽象化レベルにおいて、同じ原則を適用するというアプローチです。エントリーポイント、ビジネスロジックレベル、最下層の詳細に至るまで、すべてのレベルでコードが人間の脳に収めることを提唱しています。
この概念の基礎となるのは、認知心理学における「マジカルナンバー7±2(ミラーの法則)」です。人間の短期記憶は、同時に約7個の情報チャンク(意味のあるまとまり)しか保持できません。コードを読むとき、私たちは頭の中で小さなエミュレーターを走らせ、変数の内容を追跡し、条件分岐を評価し、ループの状態を把握します。追跡すべき要素が7個を超えると、認知負荷が過大になり、理解が困難になります。
ヘックスフラワーという視覚的メンタルモデル
フラクタルアーキテクチャを視覚化する手法として、Seemannはヘックスフラワーパターンを提示しています。中心の六角形を7つの六角形が囲む形で、それぞれの「花びら」の中にさらに六角形が入れ子になった構造です。これは単なる図ではなく、コード構造の設計図として機能します。
例えば、レストラン予約システムのバリデーション処理を考えてみましょう。中心の「ハッピーパス」(正常処理)を、7つの検証項目(メールアドレスの検証、日時の検証、人数の検証、名前の検証、座席の空き状況、DTOの検証、その他のビジネスルール)が囲みます。各検証項目はサイクロマティック複雑度7以下の独立したメソッドとして実装され、それぞれがさらに7個以下のサブ要素に分解されます。
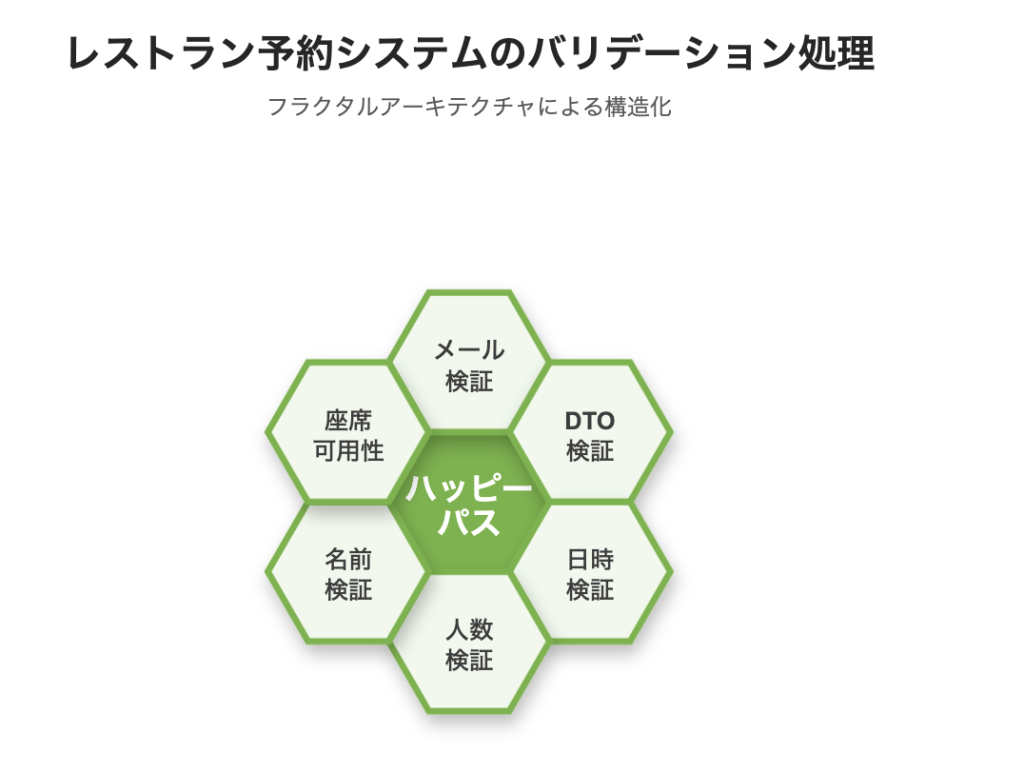
この構造により、どのレベルを見ても「脳に収まる」サイズに制限されます。自然界のフラクタル図形(木の枝や雪の結晶)と同じように、部分が全体と似た構造を持つのです。
フラクタルアーキテクチャによる、認知負荷の軽減
AIが「実装時に近視的になって全体像が見えなくなりがち」という問題に対して、フラクタルアーキテクチャはひとつの制約として貢献します。AIにコードを生成させる際、プロンプトに明示的な制約を組み込むことで、出力を管理可能な範囲に制限できます。
例えば計画フェーズでは、「この要件に関する機能は、ヘックスフラワーで整理しなさい。1つの機能・メソッドに対して、6つ以上の副作用や検証処理といった条件分岐・ループが生まれないように設計すること」のように伝えることができます。また、実装フェーズにおいても、次のような指示をAIに与えまることができます。「このバリデーション機能を実装してください。ただし、各メソッドのサイクロマティック複雑度は7以下に保ち、メソッド内で追跡する変数は7個以内にしてください。複雑な機能は、同じ制約を守る複数の小さなメソッドに分解してください。各メソッドには、その責務を明確に説明する名前を付けてください。」
この制約により、AIが生成したコードは自動的にレビュー可能なサイズになります。レビュアーは各メソッドを独立して理解でき、認知負荷が管理可能な範囲に収まります。さらに重要なのは、この構造が技術的負債の蓄積を防ぐことです。各コンポーネントが小さく理解しやすいため、将来的な変更や拡張が容易になります。
結論
生成AIによるコーディングは、ソフトウェア開発に大きな変革をもたらす可能性を秘めています。しかし現状では、認知負荷の増大、コード品質の劣化、レビューコストの上昇という深刻な問題を引き起こしています。
フラクタルアーキテクチャは、これらの問題に対する包括的なソリューションフレームワークを提供します。サイクロマティック複雑度という測定可能な基準、ヘックスフラワーという視覚的メンタルモデルを通して、人間とAIの協働における認知的インターフェースとして機能することが期待できそうです。
重要なのは、フラクタルアーキテクチャは単なる技術的パターンではなく、持続可能な開発を実現するための哲学だということです。コードは人間の脳に収まらなければならないという基本原則は、AI時代においてより重要になっています。AIが生成できるコードの量が爆発的に増加する中、人間が理解し、保守し、発展させることができる構造を維持することが、長期的な成功の鍵となります。
これからの開発組織に求められるのは、AIを盲目的に受け入れるのでも拒絶するのでもなく、人間の認知能力の限界を理解した上で、AIを適切に統制し活用する知恵です。フラクタルアーキテクチャは、その知恵を実践に移すための具体的な方法論を提供します。コードが脳に収まる限り、私たちは複雑性を制御し、質の高いソフトウェアを構築し続けることができるのです。